人工智能领域半年报(第21期)——2017年MIT人工智能的五大趋势预测2017 MIT 人工智能 5 大趋势预测
技术奇点(technological singularity)是一个根据技术发展史总结出的观点,认为未来将要发生一件不可避免的事件──技术发展将会在很短的时间内发生极大而接近于无限的进步。当此转捩点来临的时候,旧的社会模式将一去不复返,新的规则开始主宰这个世界。 50多年来,(希望模仿人类大脑的思考操作的)人工智能(Artificial Intelligence)经历了“爆发到寒冬再到野蛮生长”的历程,伴随着人机交互、机器学习、模式识别等人工智能技术的提升,机器人与人工智能成了这一技术时代的新趋势。关于人工智能的各级规划、各种预测,成为一股新的策划趋势。 本期,我们结合MIT Technology Review最近发布的2017年人工智能的五大趋势预测,探索2017年人工智能的发展路径和方向。
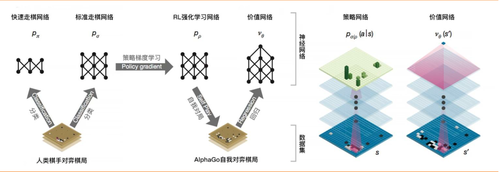
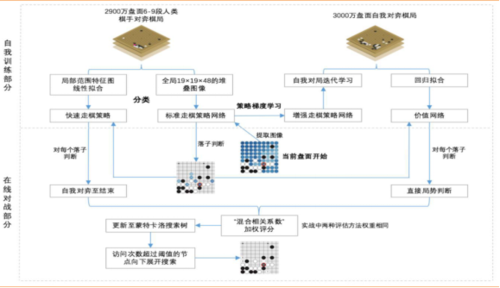
1趋势一:正向强化学习 (Positive reinforcement learning) 强化学习的灵感来自于动物的学习方式:动物能够学会某些特定行为所导致的正面或负面结果(aoutcome)。按照这种方法,计算机无需具体指示或范例(explicit examples),就可以通过试错法(trial and error)解决迷宫问题,“走出迷宫”。 尽管强化学习理论已经存在了数十年,但直到该理论与大型深度神经网络结合后,我们才真正获得了解决复杂问题(如下围棋)所需的能力。AlphaGo 与李世石的世纪大战,是深度强化学习技术的一个里程碑:通过不懈的训练与测试,以及对以前比赛的分析,AlphaGo 能够为自己找出了如何以职业棋手下棋的道路。 1.1 AlphaGo AlphaGo将(以图片形式输入系统中的)当前围棋盘面作为初始值,采用卷积神经网络(该算法同时采用(监督学习/强化学习的)“策略网络”预测下一步落子并缩小搜索范围至最有可能获胜的落子选择、采用“价值网络”减少搜索树的深度——对每一步棋局模拟预测至结束来判断是否获胜)指导其蒙特卡洛树搜索。在每一次模拟棋局中,策略网络提供落子选择、价值网络则实时判断当前局势,综合后选择最有可能获胜的落子。
图1:AlphaGo 的神经网络(资料来源:Nature) 根据DeepMind 团队发表在《自然》上的论文, AlphaGo 系统原理可归结为如下图。
图2:AlphaGo 系统原理图解(资料来源:参考 ACM 数据挖掘中国分会研究资料)
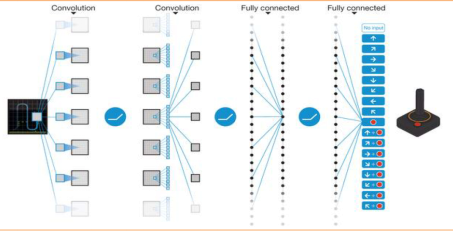
1.2游戏中的人机互动 过去一年中,DQN、Universe、Minecraft等模拟环境(simulated environments)的推出,预示强化学习将在现实世界情景中得到更多应用。 1、DeepMind的Deep Q-Network (DQN) DeepMind (2015.02,人类控制水平的深度强化学习,Nature)开发的Deep Q-Network (DQN)是将深度神经网络(Deep Neural Networks) 与(脱离模型(model free)的)强化学习(Reinforcement Learning)方法Q-Network(该方法常被用来对有限马尔科夫决策过程(Markov decision process)进行最优动作选择决策)相结合的深度强化学习系统(Deep Reinforcement Learning System)。 谷歌设计的这个可有效运用到谷歌产品服务中的DQN, 是第一个板块和领域中性(即,DeepMind不局限于在特定的板块和领域里学习)深度学习系统,通过进行端到端训练完成一系列有难度的任务。 从(二维游戏机)Atari到(3D迷宫游戏)Labyrinth、从连续控制到移动操作到围棋博弈,DeepMind 的深度强化学习智能系统在许多领域都已经表现出优异的成绩;随着算法的改进,该学习算法或将能够有效帮助不同的研究团队处理大规模的复杂数据,在气候环境、物理、医药和基因学研究领域推动新的发现,甚至能够反过来辅助科学家更好的了解人类大脑的学习机制。 (1)算法在二维动画层面游戏Atari中的优异表现 该神经网络能够使用同一套神经网络模型和参数设置(研究人员仅仅向神经网络提供了屏幕像素、具体游戏动作以及游戏分数,不包含任何关于游戏规则的先验知识)完成雅达利(Atari)游戏机2600上(从滚屏射击游戏River Raid、拳击游戏Boxing到3D赛车游戏Enduro等在内的)的49个游戏。 游戏结果显示:DQN在43个游戏中战胜了以往任何一个机器学习系统;在超过半数的游戏中,达到了职业玩家水平75%的分数水平;在个别游戏中,甚至展现了强大的游戏策略并拿到了游戏设定的最高分数。
图3:DQN 中卷积神经网络从游戏图形输入到动作控制的示意图(资料来源:Nature)
(2)算法在3D游戏Labyrinth中的良好表现 DeepMind把研究重心放到3D游戏中后,开发了一套3D迷宫游戏 Labyrinth进行深度学习系统的训练。与之前类似,智能系统只获得了在视场(field-of-view)中观察到的即时像素输入,需要找到迷宫地图的正确宝藏路径。 该技术可有效运用到谷歌产品服务中。以后,用户或许可以直接发出指令要求谷歌为他制定一个欧洲背包旅行计划。
图4:DeepMind 开发的 3D 迷宫游戏 Labyrinth 界面(资料来源:DeepMind 官网)
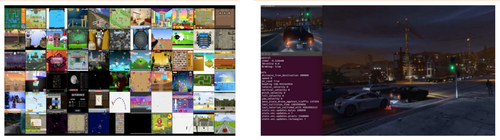
2、OpenAI的Universe:通用 vs 具体 OpenAI去年推出的Universe是用于训练解决通用问题的AI基础架构,能在几乎所有的游戏、网站和其他应用中衡量和训练AI通用智能水平的开源平台。包括了大约2600种Atari游戏、1000种flash游戏、80种浏览器环境,可供所有人用于训练人工智能系统。 OpneAI Universe一直希望开发一个单一的AI智能体,使其能够灵活运用过去在 Universe中的经验,快速在陌生和困难的环境中学习并获得技能。于近期加入了游戏大作《GTA 5》,购买正版游戏的用户可使用Universe中的人工智能在游戏中的3D环境(目前,人工智能获取视频信息的帧数被限制为8fps,环境信息和视角管理齐备)中纵横驰骋,很大程度上方便了自动驾驶模拟测试平台(如,普林斯顿大学开发的DeepDrive)在GTA世界中的测试。
图:5:Universe游戏环境范例(左图)Universe环境下的GTA5自动驾驶测试界面(右图)(资料来源:OpenAI、GitHub)
3、Minecraft 《Minecraft》是由Mojang AB和4J Studios开发的高自由度沙盒游戏(2009年5月13日上线首个版本),2014年11月6日全部资产被微软收购,2016年网易游戏取得了中国代理权。 目前,微软剑桥研究院的研究人员开发了一个Malmo项目,通过这个平台使用人工智能控制Minecraft 游戏里面的角色完成任务,研究游戏内人与AI的互动协作。该项目被视为有效的强化学习训练平台:通过特定的任务奖励,人工智能能够完成研究人员布置的游戏任务(如,控制角色从一个布满障碍物的房间的一头走到另一头);同时,人工控制的角色还会在旁边提供建议,进行人与AI协作的测试。
图6:DeepMind打造的3D训练虚拟世界(左图)、Minecraft训练界面(右图)(资料来源:DeepMind、微软)
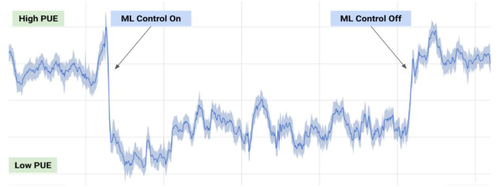
1.3更瘦、更绿的云计算数据中心 数据中心是能耗大户,多年来,谷歌一直致力于降低其云计算数据中心的能耗水平。2014年,通过安装智能温度和照明控制、采用先进的冷却技术(而非机械冷却器),最小化能量损失,将其数据中心的耗电量降到全球平均水平的50%;随后,在此能耗水平下,将现在的数据处理性能提高到5年前的3.5倍。 如今,坐拥DeepMind的谷歌将强化学习神经网络技术应用到云计算数据中心的能源控制方面:通过获取数据中心内的传感器收集的大量历史数据(如温度、功率、泵速、设定点等),首先在未来平均PUE(Power Usage Effectiveness,电力使用效率)值上训练神经网络系统(PUE是总建筑能源使用量与IT能源使用量的比率,是衡量数据中心能源效率的标准指标,而每一部仪器可以受到几十个变量的影响),而后通过不断的模拟调整模型与参数,使其接近最准确预测的配置,提高设施的实际性能;同时,团队训练两个额外的深层神经网络集合,以预测未来一小时内数据中心的温度和压力,模拟来自PUE模型的推荐行为。 18个月的模型研发与测试显示:DeepMind联合谷歌云的研发团队成功为数据中心节省了40%的冷却能耗、15%的总能耗(其中一个试点已经达到了PUE的最低点)。 未来,该技术或将用于提高发电转换效率、减少半导体生产的能量和用水量、帮助提高生产设施的产量。DeepMind 和谷歌云计算团队计划将这项成果开源出来,造福全世界的数据中心、工厂和大型建筑等。预计2017年,强化学习将更多的出现在自动驾驶系统、工业机器人控制等方面。
图7:数据中心 PUE 的机器学习测试结果(资料来源:DeepMind)
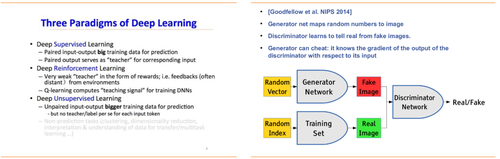
2趋势二:对抗性神经网络 (Dueling neural networks) OpenAI科学家Ian Goodfellow发明的生成式对抗网络(generative adversarial networks, GAN)协同使用“从训练集合中学习后生成新数据”和“区分真实和虚假数据”的两个相互博弈网络组成的系统,产生非常逼真的合成数据,可用于生成视频游戏的场景、清晰被像素化的视频画面、生成更有时尚感的计算机设计。 该方法为计算机提供了一种从未标记数据中学习的有效方法(Yoshua Bengio,蒙特利尔大学机器学习专家,Ian Goodfellow的博士导师),能训练任何一种生成器网络(见图8),很可能是在无监督学习(unsupervised learning)还没能普及之前让计算机变得更加智能的关键。
图8:深度学习的三类学习模式(左图)、生成式对抗网络(GAN)的原理示意(右图)(资料来源:人工智能大会PPT、NIPS)
3趋势三:中国的人工智能热潮 (China's AI boom) 在企业的自发努力和政府的积极推动下,中国科技企业开始倾向于自主研究人工智能和机器学习、中国投资者对人工智能创业公司的投资热情正在明显上涨,接下来的1-3年将是很多人工智能技术的关键阶段:2017年或将是中国开始成为人工智能领域主要参与者的一年,预计在2018年前投资约150亿美元。 3.1百度的AI布局 百度在AI的战略布局包括2013年的硅谷人工智能实验室、深度学习实验室、大数据实验室,这些实验室的主要研究领域包括图像识别、语音识别、自然语言处理、机器人和大数据。目前,百度已经在语音识别和自然语言处理、广告优化等领域有所建树,2016年9月、2017年1月,相继发布了百度大脑(包括PaddlePaddle深度学习平台(算法模型)、AI超级计算机(底层技术)、大数据三大核心技术)、百度人工智能操作系统 DuerOS。 1、语音识别Deep Speech 2 2015年11月,百度硅谷实验室在吴恩达教授(Professor Andrew Ng)指导下研发出了新一代深度语音识别系统Deep Speech 2。该系统(同样)使用联结主义时间分类技术(Connectionist Temporal Classification, CTC)的损失函数,在16个GPU上对网络进行端到端训练,使来自输入音频的字符序列可以被直接预测。 百度研究人员表示,在噪音环境中(比如,汽车内、人群之中),测试显示百度 Deep Speech系统的出错率较(谷歌的)API、(Facebook的)Wit.AI、(微软的)Bing Speech、(苹果的)Dictation低约 10%。
图9:Deep Speech与Dictation、Bing Speech、wit.ai、API的语音识别错误率比较(左图)、Deep Speech 2 用于英文和中文的深度RNN结构(右图)(资料来源:百度USA、百度人工智能实验室)
2、图像识别 百度深度学习研究院围绕图像识别,在图像识别基本技术、细粒度图像识别(fine-grained image recognition)、视频分析、AR技术、医学图像分析等方面开展了诸多工作:(1)在图像识别基本技术中,其光学字符识别(OCR)技术已经排到世界前列,手机端身份证识别准确率达到99%以上;(2)在细粒度图像识别中,其2016年9月上线的糯米应用的新功能,在机器学习了用户拍摄的菜品图片后,可以识别出是哪家餐馆的具体哪道菜品,并推荐用户附件5公里内最佳的餐厅;(3)在视频分析方面,百度希望将技术运用到无人驾驶的图像识别领域,目前主攻的方向是视频分割以及3D重建;(4)在AR方面,百度已经可以通过向视频拍摄画面叠加动画效果。
3.2腾讯、阿里纷纷赶上 1、腾讯的AI布局 腾讯在AI的战略布局是2016年4月的AI实验室,该实验室基于业务整合考虑,围绕计算机视觉(Computer Vision)、语音识别(Speech Recognition)、自然语言处理(NLP)、机器学习(Machine Learning)等四个领域,主攻内容AI、社交AI、游戏AI、具类AI等四个研究方向:(1)在深度学习方面,2016年12月,腾讯大数据推出了与香港科技大学、北京大学联合研发的第三代高性能计算平台Angel;(2)在人工智能云服务方面,2016年12月,腾讯云宣布向全球企业正式提供(人脸检测、五官定位、人脸比对与验证、人脸检索、图片标签、身份证OCR识别、名片OCR识别等)7项AI云服务;(3)在无人车方面,腾讯注资的滴滴出行于2016年4月(将原先成立的机器学习研究院更名为滴滴研究院,)开始探索“通过结合大数据和机器学习,搭建滴滴交通大脑”的路径,初步在滴滴出行目的地预测、路径规划、拼车最优匹配、订单分配、估价、运力调度、评分系统等方面应用了机器学习。此外,滴滴收购优步中国、智能交通云平台的开发、Di-Tech算法大赛的举办,也快了滴滴未来开发无人驾驶共享汽车的脚步。
2、阿里的AI布局 阿里认为:(1)(交易、资产配置、信用等)金融生活是数字数据的体现,所以这方面深度学习能够发挥作用;(2)金融行业的规模足够巨大,能有效推动人工智能的应用和发展。因此,其在AI的战略布局是,借助自身的电商平台优势,重点布局人工智能在金融领域的应用:(1)借助电商平台的优势,2015年7月发布了人工智能购物助理虚拟机器人“阿里小蜜”;(2)在金融领域方面,①通过机器学习,将蚂蚁微贷和花呗的虚假交易率降低了10倍;②支付宝的证件审核系统开发的OCR系统,使证件校核时间从1天缩小到1秒,同时提升了30%的通过率;③蚂蚁金服以信用为基础,将人工智能技术运用于蚂蚁微贷、保险、征信、风险控制、客户服务等多个领域,(以智能客服为例,)2015年“双11”期间,蚂蚁金服的大数据智能机器人(以100%自动语音识别)完成了95%的远程客户服务。
4趋势四:语言学习 (Language learning) 人们希望,有朝一日,计算机可以通过语言与我们交流和互动。AI研究人员正致力于提升语音和图像识别等领域的技术,帮助计算机更好的理解语言的上下文含义(从而更有效地分析和生成语言),进而对自己的决策行为作出说明(可以反过来给予科学家更多的灵感),提升AI系统的实用性。 但鉴于语言的复杂性、微妙性、多语种歧义性,短时间内,用户和智能手机还不能进行深入和有意义的对话,但语音识别和语音接口在技术和应用场景方面均较为成熟,(谷歌助理、亚马逊Alexa等)一些令人印象深刻的进步正在进行。2017年,我们可以期待在这一领域看到更进一步的发展。 4.1Google Home与亚马逊Echo的正面交锋 谷歌在为智能手机、平板、智能手表配备谷歌助理之后,(2016.10.04)进一步推出内置了谷歌助理的无线音箱Google Home(售价129美元),完善并吸引用户进入其智能生态圈。这款由Chromecast团队主导开发的谷歌智能生活入口设备,像一个随时待命的具象化的虚拟助理,能够调用谷歌搜索以及其他应用程序,用户通过语音指令,控制它执行播放音乐、关闭房间照明、回答知识性问题、查询交通状况、更改预约等任务。(承载着谷歌在物联网和智能家居领域新希望的)该产品和(亚马逊广受欢迎的智能音箱)Echo均主打语音控制、人工智能助理、将各类用户常用的第三方生活场景应用接入自身智能生态圈,因而成为直接对手,但两者在语音接收处理、功能略有不同。 1、外观和语音接收方面的差别 亚马逊Echo是一个黑色的柱状音箱,同时配有一个内置麦克风的无线遥控器。音箱(内置的7个麦克风接收器组成的矩阵)使用音波聚束技术探测远场声音、配合增强的噪音消除技术,使得Echo即使在播放音乐时也能听清用户的语音提问指令;当用户所在位置的语音指令不能被Echo接收到时,无线遥控器就显得非常便利。 Google Home使用了“花瓶型”的更圆润而精致线条设计,该机身顶部斜面(隐藏了四种颜色LED灯的)可触控表面显示当前的音量级别(当有用户语音指令处理时,4色的LED灯就会亮起),背面设置的“关闭麦克风”按钮(同时加入了手指在按钮上旋转来控制音量的操作)可以用来暂停或播放音乐,(音箱)底部(多种颜色和材质)的扬声器格栅使用磁铁吸附。此外,Google Home使用定制的AC电源(取代USB电源)保证内置3英寸扬声器的声音足够持续稳定填满整个房间。
图10:Google Home产品宣传图(左图)、Google Home和亚马逊Echo外观对比(右图)(资料来源:谷歌 2016 I/O 大会现场照片、Wired及Engadget等)
Echo与Google Home最关键的区别在于麦克风的数量与阵列:Echo使用了7个麦克风的结构,而Google Home只有2个(原理上,麦克风越多,越能收集到来自不同方位的远场声音,并从环境噪音中识别出用户指令,例如Echo的远程声音识别)。谷歌表示,他们通过云端机器学习算法(例如自然语意处理)对2个麦克风进行的调试显示:他们使用的2个麦克风能达到(Echo)7麦克风相同的效果。此外,外媒测评显示,同一间屋子里的几个不同的Google Home可以同时响应用户语音指令(例如,同时播放歌曲),这是谷歌从一开始就设计的多房间支持(Multi-room capability)。
图11:Google Home 2个麦克风设计(左图)、Echo的7个麦克风矩阵:远程语音识别(右图)(资料来源:Wired、Engadget等 )
2、功能方面的差别 亚马逊Echo最精明的地方是可以出现在第三方设备和服务中:(1)不仅可以在亚马逊平台上购物和播放Prime音乐,还可以让用户选择Pandora、Spotify等娱乐,购买达美乐披萨外卖、获得Yelp点评的功能、Uber打车服务等;(2)在智能家居应用方面,与三星、飞利浦、Belkin、Ecobee等合作,将他们的智能家居设备整合到Echo的控制系统中。也正是因为亚马逊基于其电商基础,将Echo做成Prime电商服务的语音入口,使用户在Echo上可以要求Alexa重新下单已经购买过的商品、为用户推荐亚马逊Prime类别下的各类商品(并由亚马逊管理配送,在2天内送达),所以吸引了更多用户在亚马逊上购物及参与成为Prime会员。Slice Intelligence的报告显示:Echo用户都是“亚马逊重度消费者”,他们比非 Echo用户在亚马逊上的花费多7%(这也给了亚马逊更多的用户消费数据,从而提高消费者体验)。 谷歌根据其收集的(用户每日的日程安排、地图搜索、邮件收发等行为等)用户日常生活行为习惯数据,为用户提供更多网络服务内容,并致力于智能家居方面的拓展(由于谷歌在用户消费数据上无法与亚马逊相比,Google Home目前暂不支持软件内支付,因此目前无法通过Home进行网购消费):(1)谷歌遍布全世界的(音频、视频)网络服务内容给用户带来更多的可选性:①谷歌2015年1月推出的Google Cast软件,整合了(自己的)Play、Spotify、Pandora、iHeart广播等音乐服务,不仅为用户提供了丰富的音乐内容,还便于使用iOS和Android设备的用户将手机中的音乐推送到Home中播放;②用户可以指挥(由Chromecast团队主导开发的)Home搜索播放YouTube、Netflix上的视频,并通过安装了Chromecast 的电视屏幕自动播放出来,从而使得Chromecast与电视屏幕成为Google Home的一个可视化的界面。(2)在智能家居应用方面,谷歌计划率先将(其拥有的智能家居市场最受关注品牌)Nest旗下的(包括智能学习恒温器、烟雾探测器、智能监控摄像头等)器件整合进Home智能家居系统平台,并与飞利浦Hue、IFTTT、三星旗下的SmartThings平台等建立了合作(希望在年内指导更多的第三方厂商将智能家居设备和应用整合到谷歌助理中)。 虽然两家公司都在建立自己的智能生态圈,但是,布局先人一步的亚马逊很可能依靠Echo的明星效应和Alexa的开源布局抢滩智能家居市场。市场调研机构CIRP的统计显示:Echo自2014年底推出以来,已经卖出了约510万台(其中,2016年前九个月卖出约200万台),其新近推出的Echo Dot和Echo Tap(这两者比传统Echo更小更便宜)在过去六个月贡献了至少33%的销售额。
图:12:内置Alexa的LG智能冰箱(左图)及其配置的29寸触摸屏(右图)(资料来源:Engadget、CNET)
4.2谷歌的Allo智能回复 谷歌在将智能回复应用到邮件服务Gmail / Inbox中后,进一步将该功能应用到聊天软件而推出Allo:该聊天软件可以先通过对用户的对话记录来生成“标准化”智能回复选项,再在随后的不断学习“用户的个人说话方式”过程中(更优化地理解用户的对话语义)逐渐生成“私人定制”的智能回复。 1、生成“标准化”智能回复 Allo团队使用了一个类似“编码-解码”两步模型的方法:(1)首先使用一个递归神经网络将对话语句一个词一个词进行编码生成对应口令(token),然后口令进入长短期记忆神经网络(Long-short term memory, LSTM)生成一个连续向量,随后这个连续向量进一步通过softmax模型生成一个(包含一组可以用来回复的可选择单词组的)离散语义结构(discretized semantic class)。(2)接着使用第二个递归神经网络从可选择单词组中挑出最合适的回复、并让离散语义结构进入长短期记忆神经网络(LSTM)(一次一个口令的)生成完整的回复消息,然后解码成为自然语义单词。如下图所示,当提问句为“Where are you?”时,神经网络会将问句三个单词生成 3 个口令,然后进行下一步处理;经过第二个递归神经网络中的长短期记忆神经网络(LSTM)处理,系统生成了对刚才“Where are you?”提问的回答“I’m at work”。
图:13:神经网络将问句三个单词生成3个口令(左图)、谷歌语音识别神经网络的输出示意图(右图)(资料来源:谷歌研究所官方博客)
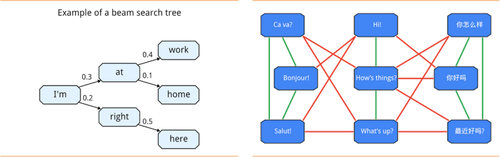
Allo团队提及,为了保证软件及时(不使用户失去使用的耐心)生成长度适中(如果过长就不能适应手机屏幕,如果过短会造成可用性不强)的回复选项,他们(1)将模型第一部分中的softmax算法改成分层式softmax算法(即,将对可选择单词组的遍历从单词列表遍历改为了单词树遍历),成功将递归神经网络的延迟时间从0.5秒缩短到200毫秒以下;(2)在第二部分使用定向搜索(beam search)技术(该技术一般用来对搜索域中最优解进行向下拓展的启发式搜索)挑选离散语义结构所包含的可选单词组、并将定向搜索算法的倾向调整为去搜索使用效率更高的单词组路径,提高了回复单词组的选择效率、保证了生成的回复选项长度适中。
2、“私人定制”回复及多语言关联 Allo团队表示,他们在神经网络训练中添加了“用户嵌入”(user embedding)项学习用户的“说话风格”,使用了L-BFGS(Limited-memory Broyden Fletcher Goldfarb Shanno或在受限内存时的拟牛顿算法)迅速生成海量“用户嵌入”数据,使得Allo的智能回复会随着用户的使用时间增加而更加反映用户的说话习惯。例如,当用户在回答“How are you?”时习惯使用“Fine”而不是“I'm good”,Allo会把这些习惯添加到神经网络中,把“说话风格”作为神经网络的一个参数项来进行回复推荐(如下图所示)。 此外,开发团队使用基于(半监督学习(Semi-supervised)语义理解的)图表关联(graph-based)的机器学习技术进行多语言之间的相互关联,并连接了谷歌机器翻译团队的模型来进行单词翻译,使得Allo的智能回复适用于所有语言。 (注:半监督学习(Semi-supervised Learning)技术是监督式学习(Supervised与非监督学习(Unsupervised Learning)相结合的一种学习方法,它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。)
图14:神经网络将问句三个单词生成3个口令(左图)、谷歌语音识别神经网络的输出示意图(右图)(资料来源:谷歌研究所官方博客)
4.3神经机器翻译系统 1、翻译基础 10年前,谷歌发布了谷歌翻译(该系统的核心算法是基于短语的机器翻译技术(Phrase-Based Machine Translation, PBMT))并随即将递归神经网络RNN加入机器翻译中,直接学习输入端(一种语言的一个句子)到输出端(另一种语言的同一句子)的映射,实现了机器翻译,但(这种将句子中的词和短语拆分进行独立翻译的做法)却很容易出现罕见词不识别、上下文意不通的情况。 最近,谷歌发布了谷歌神经机器翻译(Google Neural Machine Translation system, GNMT),该系统使用的神经机器翻译系统(NMT)将整个句子视作翻译的基本输入单元(NMT相对于PBMT的优势在于能够减少工程设计。并且,随着NMT的不断改进,研究人员又加入了外部对准模型(External Alignment Model)来标记罕见词),进行直接的端到端训练,实现了机器翻译技术迄今为止的最大进步。谷歌翻译、有道翻译、百度翻译分别对“小偷偷偷偷东西”的翻译结果显示:基于句子的(谷歌)机器翻译优于基于短语的(有道、百度)机器翻译。
图:15:谷歌翻译、有道翻译、百度翻译实例对比(资料来源:各翻译软件)
2、翻译机制 谷歌神经机器翻译系统使用了深度长短期记忆神经网络LSTM,该神经网络由8个编码器和8个解码器组成、使用注意链接(attention connections)和残差连接(residual connections)连接编码器与解码器。例如,汉英翻译时,系统先将输入的汉语句子的词编码成一个向量列表(其中每个向量都表征了到目前为止所有被读取到的词的含义(即编码器)),读取完整个句子后,解码器重点“注意”与生成英语词最相关的编码的汉语向量的权重分布,一次生成英语句子的一个词(即解码器)。
图16:谷歌神经机器翻译系统(GNMT)翻译机制(资料来源:谷歌研究所官方博客) 此外,在该翻译系统中,(1)注意连接机制将解码器的底层连接到了编码器的顶层,提升了并行性并降低训练时间;(2)谷歌在推理运算时使用低精度算法,增加了最终翻译速度;(3)谷歌将词组分为由常见词组成的子词单元(sub-word units)的有限集合,同时作为输入和输出内容,有效平衡了“字符(character)”限定模型(delimited models)的灵活性与“词(word)”限定模型的有效性,自然地处理了罕见词翻译,进而提升了整体翻译质量。
3、翻译系统的适用范围 此次由Google Brain和谷歌翻译团队共同开发完成的系统,使用了谷歌的开源机器学习平台TensorFlow和张量处理单元TPU,保证了系统的计算能力和严格的延迟要求。测试结果表明:新系统在多个主要语言的翻译中将翻译误差降低了 55%-85%以上。特别是在英语到西班牙语的翻译中(满分6分),新系统的平均得分(5.43分)与人类翻译的平均得分(5.55分)相差无几。目前,谷歌翻译的汉英翻译已经在使用这套系统完成所有的翻译请求(约1800万条/天),未来几个月,谷歌将会把GNMT扩展到更多的语言翻译上。
图17:满分6分记,人类翻译、谷歌神经翻译与PBMT的得分对比(资料来源:谷歌研究所官方博客)
不过,Google Brain的成员同时表示,由于人类语言在不断进步、不断出现新生词汇,无法在任何情况下都使用机器翻译替换人类翻译,但在(论文、科技文献等)结构化比较高、(新闻时事短讯等)写作思路比较固定且读者不太关注文笔而更注重信息传达的文章中,(基于已经出现过的语言现象的)机器翻译能够非常快的提高翻译精确度。
5趋势五:反对人工智能过度炒作 (Backlash to the hype) 虽然许多人对于目前正在开发的人工智能技术的潜在价值抱有信心,2016年也确实发生了不少实在的进步和令人兴奋的新应用,但我们也发现:(1)在媒体、大型公司、投资者的不断曝光下,人工智能已经成为科技聚光灯下的主角,(EY的报告显示,)2015、2016年与AI相关并购分别有33、46项,曝光度偏高;(2)目前许多不断强调机器学习技术的创业公司其实大多名不副实,这方面的典型是Rocket AI(NIPS大会为Rocket AI的虚假人工智能公司举行的发布会,实际上是要讽刺围绕人工智能研究日益增长的狂热与夸大)。 我们认为,人工智能现在才是春天,在重大突破没有发生时,过多的炒作很可能会对这个新兴行业造成揠苗助长的负面效果(这种情况让业内人士感觉不安):不仅将研究者的注意力过早从人工智能的理论和研究转向创业,还使得企业在并购时,不得不面对过高的溢价和估值,从而导致创业公司因估值过高而加速步向失败以及投资枯竭的情况。 人工智能其实才刚刚起步,很多方面还有提升空间。在2017年,我们应该冷静的看待AI行业的下一步发展,兼听则明地听取一些对人工智能炒作的反对声音。2017年会是AI最好的时代,还是最坏的时代?值得期待。
通讯地址:上海市南京东路800号 新一百大厦17楼 联系人:陈海燕 联系方式:chenhy@chinardr.net
|