人工智能领域简报(2018年 第19期)——深度学习选GPU,RTX 20系列值不值得?深度学习常被戏谑为“炼丹术”,那么,GPU于深度学习研究人员而言就是不可或缺的“炼丹炉”。 深度学习是一个计算要求很高的领域,选择什么 GPU、选择多少个 GPU 将从根本上决定你的深度学习体验。如果没有 GPU,可能需要好几个月等待实验完成,或者实验运行一整天下来只是看到失败的结果。 凭借良好、可靠的 GPU,炼丹师们可以快速迭代深度网络的设计和参数,运行实验的时间只需几天而不是几个月,几小时而不是几天,几分钟而不是几小时。 因此,在购买 GPU 时做出正确的选择至关重要。
Tim Dettmers 的GPU选择 那么如何选择适合你的 GPU 呢?本文作者 Tim Dettmers 是瑞士卢加诺大学信息学硕士,热衷于开发自己的 GPU 集群和算法来加速深度学习。这篇文章深入研究这个问题,并提供建议,帮你做出最合适的选择。 本周 NVIDIA 震撼发布的 GeForce RTX 20 系列显卡值不值得买?它的能力、性价比如何?本文也给出分析。 先放结论:RTX 2080 最具成本效益的选择。当然,GTX 1080/1070(+ Ti)卡仍然是非常好的选择。
作者给出的GPU建议如下:
NVIDIA: 绝对王者 NVIDIA 的标准库使得在 CUDA 中建立第一个深度学习库变得非常容易,而 AMD 的 OpenCL 却没有这样强大的标准库。这种领先优势,再加上英伟达强大的社区支持,迅速扩大了 CUDA 社区的规模。这意味着,如果你使用 NVIDIA GPU,在遇到问题时可以很容易找到支持;如果你自己写 CUDA 程序,也很容易找到支持和建议,并且你会发现大多数深度学习库都对 NVIDIA GPU 提供最佳支持。对于 NVIDIA GPU 来说,这是非常强大的优势。 另一方面,英伟达现在有一项政策,在数据中心使用 CUDA 只允许 Tesla GPU,而不允许使用 GTX 或 RTX 卡。“数据中心” 的含义模糊不清,但这意味着,由于担心法律问题,研究机构和大学往往被迫购买昂贵而且成本效率低的 Tesla GPU。然而,Tesla 卡与 GTX 和 RTX 卡相比并无大的优势,价格却要高 10 倍。 英伟达能够没有任何大障碍地实施这些政策,这显示出其垄断力量——他们可以随心所欲,我们必须接受这些条款。如果你选择了 NVIDIA GPU 在社区和支持方面的主要优势,你还需要接受他们的随意摆布。 AMD:能力强大,但缺乏支持 HIP 通过 ROCm 将 NVIDIA 和 AMD 的 GPU 统一在一种通用编程语言之下,在编译成 GPU 汇编代码之前被编译成各自的 GPU 语言。如果我们的所有 GPU 代码都在 HIP 中,这将成为一个重要里程碑,但这是相当困难的,因为 TensorFlow 和 PyTorch 代码基很难移植。TensorFlow 对 AMD GPU 有一些支持,所有的主要网络都可以在 AMD GPU 上运行,但是如果你想开发新的网络,可能会遗漏一些细节,这可能阻止你实现想要的结果。ROCm 社区也不是很大,因此要快速解决问题并不容易。此外,AMD 似乎也没有太多资金用于深度学习开发和支持,这减缓了发展的势头。 但是,AMD GPU 性能并不比 NVIDIA GPU 表现差,而且下一代 AMD GPU Vega 20 将会是计算能力非常强大的处理器,具有类似 Tensor Core 的计算单元。 总的来说,对于那些只希望 GPU 能够顺利运行的普通用户,我仍然无法明确推荐 AMD GPU。更有经验的用户应该遇到的问题不多,并且支持 AMD GPU 和 ROCm / HIP 开发人员有助于打击英伟达的垄断地位,从长远来看,这将为每个人带来好处。如果你是 GPU 开发人员并希望为 GPU 计算做出重要贡献,那么 AMD GPU 可能是长期产生良好影响的最佳方式。对于其他人来说,NVIDIA GPU 是更安全的选择。 英特尔:仍需努力 我个人对英特尔 Xeon Phis 的经验非常令人失望,我认为它们不是 NVIDIA 或 AMD 显卡的真正竞争对手:如果你决定使用 Xeon Phi,请注意,你遇到问题时能得到的支持很有限,计算代码段比 CPU 慢,编写优化代码非常困难,不完全支持 c++ 11 特征,不支持一些重要的 GPU 设计模式编译器,与其他以来 BLAS routine 的库(例如 NumPy 和 SciPy))的兼容性差,以及可能还有许多我没遇到的挫折。 我很期待英特尔 Nervana 神经网络处理器(NNP),因为它的规格非常强大,它可以允许新的算法,可能重新定义神经网络的使用方式。NNP 计划在 2019 年第三季度 / 第四季度发布。 谷歌:按需处理更便宜? Google TPU 已经发展成为非常成熟的基于云的产品,具有极高的成本效益。理解 TPU 最简单的方法是将它看作多个打包在一起的 GPU。如果我们看一下支持 Tensor Core 的 V100 和 TPUv2 的性能指标,我们会发现对于 ResNet50,这两个系统的性能几乎相同。但是,谷歌 TPU 更划算。 那么,TPU 是不是基于云的经济高效的解决方案呢?可以说是,也可以说不是。不管在论文上还是在日常使用上,TPU 都更具成本效益。但是,如果你使用 fastai 团队的最佳实践和指南以及 fastai 库,你可以以更低的价格实现更快的收敛——至少对于用卷及网络进行对象识别来说是这样。 使用相同的软件,TPU 甚至可以更具成本效益,但这也存在问题:(1)TPU 不能用于 fastai 库,即 PyTorch;(2)TPU 算法主要依赖于谷歌内部团队,(3)没有统一的高层库可以为 TensorFlow 实施良好的标准。 这三点都打击了 TPU,因为它需要单独的软件才能跟上深度学习的新算法。我相信谷歌的团队已经完成了这些工作,但是还不清楚对某些模型的支持有多好。例如,TPU 的官方 GitHub 库只有一个 NLP 模型,其余的都是计算机视觉模型。所有模型都使用卷积,没有一个是循环神经网络。不过,随着时间的推移,软件支持很可能会迅速改进,并且成本会进一步下降,使 TPU 成为一个有吸引力的选择。不过,目前 TPU 似乎最适合用于计算机视觉,并作为其他计算资源的补充,而不是主要的深度学习资源。 亚马逊:可靠但价格昂贵 自从上次更新这篇博文以来,AWS 已经添加了很多新的 GPU。但是,价格仍然有点高。如果你突然需要额外的计算,例如在研究论文 deadline 之前所有 GPU 都在使用,AWS GPU instances 可能是一个非常有用的解决方案 然而,如果它有成本效益,那么就应该确保只运行几个网络,并且确切地知道为训练运行选择的参数是接近最优的。否则,成本效益会大大降低,还不如专用 GPU 有用。即使快速的 AWS GPU 是诱人的坚实的 gtx1070 和 up 将能够提供良好的计算性能一年或两年没有太多的成本。 总结而言,AWS GPU instance 非常有用,但需要明智而谨慎地使用它们,以确保成本效益。有关云计算,我们后面还会再讨论。 选择 GPU 时,你的第一个问题可能是:对于深度学习来说,使得 GPU 运算速度快的最重要的特性是什么?是 CUDA Core,时钟速度,还是 RAM 的大小? 虽然一个很好的简化建议应该是 “注意内存带宽”,但我不再建议这样做。这是因为 GPU 硬件和软件多年来的开发方式使得 GPU 的带宽不再是其性能的最佳指标。在消费级 GPU 中引入 Tensor Core 进一步复杂化了这个问题。现在,带宽、FLOPS 和 Tensor Core 的组合才是 GPU 性能的最佳指标。 为了加深理解,做出明智的选择,最好要了解一下硬件的哪些部分使 GPU 能够快速执行两种最重要的张量操作:矩阵乘法和卷积。 考虑矩阵乘法的一个简单而有效的方法是:它是受带宽约束的。如果你想使用 LSTM 和其他需要做很多矩阵乘法的循环网络的话,内存带宽是 GPU 最重要的特性,
Tensor Cores 稍微改变了这种平衡。Tensor Cores 是专用计算单元,可以加速计算——但不会加大内存带宽——因此对于卷积网络来说,最大的好处是 Tensor Core 可以使速度加快 30%到 100%。 虽然 Tensor Cores 只能加快计算速度,但它们也允许使用 16-bit 数字进行计算。这也是矩阵乘法的一大优点,因为数字的大小只有 16-bit 而不是 32-bit,在内存带宽相同的矩阵中,数字的数量可以传输两倍。一般来说,使用 Tensor Cores 的 LSTM 可以加速 20% 到 60%。 请注意,这种加速并不是来自 Tensor Cores 本身,而是来自它进行 16-bit 计算的能力。在 AMD GPU 上的 16-bit 算法和在 NVIDIA 的具有 Tensor Cores 的卡上的矩阵乘法算法一样快。 Tensor Cores 的一个大问题是它们需要 16-bit 浮点输入数据,这可能会带来一些软件支持问题,因为网络通常使用 32-bit 的值。如果没有 16-bit 的输入,Tensor Cores 就相当于没用的。 但是,我认为这些问题很快就能得到解决,因为 Tensor Cores 太强大了,现在消费级 GPU 也使用 Tensor Cores,因此,将会有越来越多的人使用它们。随着 16-bit 深度学习的引入,我们实际上使 GPU 的内存翻倍了,因为同样内存的 GPU 中包含的参数翻倍了。 总的来说,最好的经验法则是:如果你使用 RNN,要看带宽;如果使用卷积,就看看 FLOPS;如果你买得起,就考虑 Tensor Cores(除非必要,否则不要买 Tesla 卡)
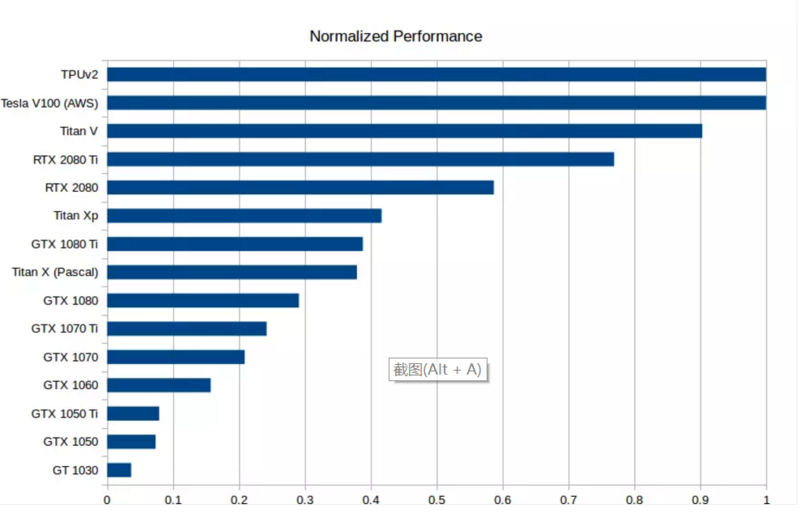
GPU 和 TPU 的标准化原始性能数据。越高越好。 RTX 2080 Ti 的速度大约是 GTX1080 Ti 的两倍:0.75 vs 0.4。 性价比也许是选择 GPU 时要考虑的最重要的一类指标。我对此做了一个新的成本性能分析,其中考虑了内存位宽、运算速度和 Tensor 核心。价格上,我参考了亚马逊和 eBay 上的价格,参考权重比为 1:1。然后我考察了使用 / 不使用 Tensor Core 情况下的 LSTM、CNN 等性能指标。将这些指标数字通过标准化几何平均得到平均性能评分,计算出性价比数字,结果如下:
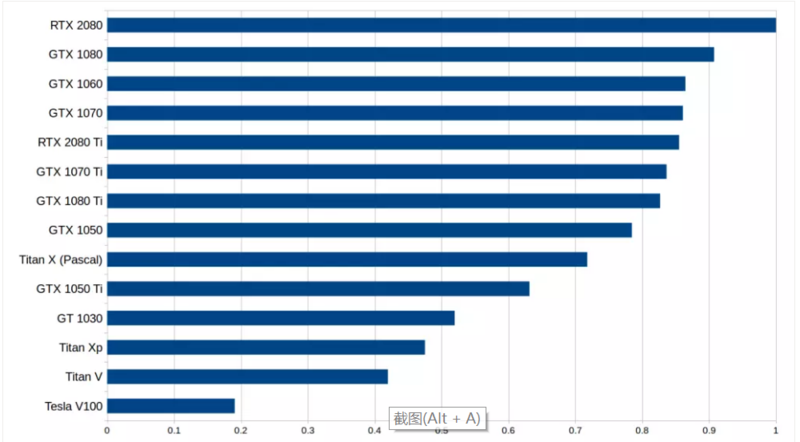
标准化处理后的性价比结果,考虑了内存带宽(RNN)、计算速度(卷积网络)、是否使用 Tensor Cores 等因素,数字越高越好。RTX2080 的性价比大概是 Tesla V100 的 5 倍。 请注意,RTX 2080 和 RTX 2080 Ti 的数字可能有些水分,因为实际的硬性能数据还未发布。我根据这个硬件下的矩阵乘法和卷积的 roofline 模型以及来自 V100 和 Titan V 的 Tensor Core 基准数字来估计性能。由于目前没有硬件规格数字,RTX 2070 完全没有排入。注意,RTX 2070 可能很容易在成本效益上击败其他两款 RTX 系列显卡,但目前没有数据支持。 从初步数据来看,我们发现 RTX 2080 比 RTX 2080 Ti 的性价比更高。 与 RTX2080 相比,RTX 2080 Ti 的 Tensor 核心和带宽增加了约 40%,价格提高了 50%,但性能并没有提高 40%。对于 LSTM 和其他 RNN 来说,从 GTX 10 系到 RTX 20 系的性能增长,主要是在于支持了 16 位浮点计算,而不是 Tensor 核心本身。虽然卷积网络的性能在理论上应该与 Tensor 核心呈线性增加,但我们从性能数据中并没有看出这一点。 这表明,卷积体系结构的其他部分无法凭借 Tensor 核心获得性能提升,而这些部分在整体计算需求中也占了很大比重。因此,RTX 2080 具有更高的性价比,因为它具有比 GTX 10 系列获得性能提升(GDDR6 + Tensor 核心)所需的所有功能,同时也比 RTX 2080 Ti 更便宜。 此外请读者注意,这个分析中存在一些问题,对这些数据的解释需要慎重: (1)如果你购买的是高性价比、但运算速度较慢的显卡,那么在某些时候计算机可能不再会有更多 GPU 空间,因此会造成资源浪费。因此,本图表偏向于昂贵的 GPU。为了抵消这种偏差,还应该对原始性能图表进行评估。 (2)此性价比图表假设,读者会尽量多地使用 16 位计算和 Tensor 内核。也就是说,对于 32 位计算而言,RTX 系显卡的性价比很低。 (3)此前有传闻说,有大量的 RTX 20 系显卡由于加密货币行情的下滑而被延缓发布。因此,像 GTX 1080 和 GTX 1070 这样流行的挖矿 GPU 可能会迅速降价,其性价比可能会迅速提高,使得 RTX 20 系列在性价比方面不那么有优势。另一方面,大量的 RTX 20 系显卡的价格将保持稳定,以确保其具备竞争力。很难预测这些显卡的后续前景。 (4)如前文所述,目前还没有关于 RTX 显卡硬性、无偏见的性能数据,因此所有这些数字都不能太当真。 可以看出,在这么多显卡中做出正确选择并不容易。但是,如果读者对所有这些问题采取一种平衡的观点,其实还是能够做出自己的最佳选择的。 AWS 上的 GPU 实例和 Google Cloud 中的 TPU 都是深度学习的可行选择。虽然 TPU 稍微便宜一点,但它缺乏 AWS GPU 的多功能性和灵活性。 TPU 可能是训练目标识别模型的首选。但对于其他类型的工作负载,AWS GPU 可能是更安全的选择。部署云端实例的好处在于可以随时在 GPU 和 TPU 之间切换,甚至可以同时使用它们。 但是,请注意这种场景下的机会成本问题:如果读者学习了使用 AWS 实例能够顺利完成工作流程的技能,那么也就失去了利用个人 GPU 进行工作的时间,也无法获得使用 TPU 的技能。而如果使用个人 GPU,就无法通过云扩展到更多 GPU / TPU 上。如果使用 TPU,就无法使用 TensorFlow,而且,切换到 AWS 平台并不是一件很容易的事。流畅的云工作流程的学习成本是非常高的,如果选择 TPU 或 AWS GPU,应该仔细衡量一下这个成本。 另一个问题是关于何时使用云服务。如果读者想学习深度学习或者需要设计原型,那么使用个人 GPU 可能是最好的选择,因为云实例可能成本昂贵。但是,一旦找到了良好的深度网络配置,并且只想使用与云实例的数据并行性来训练模型,使用云服务是一种可靠的途径。也就是说,要做原型设计,使用小型 GPU 就够了,也可以依赖云计算的强大功能来扩大实验规模,实现更复杂的计算。 如果你的资金不足,使用云计算实例也可能是一个很好的解决方案,但问题是,当你只需要一点点原型设计时,还是只能分时购买大量计算力,造成成本和计算力的浪费。在这种情况下,人们可能希望在 CPU 上进行原型设计,然后在 GPU / TPU 实例上进行快速训练。这并不是最优的工作流程,因为在 CPU 上进行原型设计可能是非常痛苦的,但它确实是一种经济高效的解决方案。 在本文中,读者应该能够了解哪种 GPU 适合自己。总的来说,我认为在选择 GPU 是有两个主要策略:要么现在就使用 RTX 20 系列 GPU 实现快速升级,或者先使用便宜的 GTX 10 系列 GPU,在 RTX Titan 上市后再进行升级。如果对性能没那么看重,或者干脆不需要高性能,比如 Kaggle 数据竞赛、创业公司、原型设计或学习深度学习,那么相对廉价的 GTX 10 系列 GPU 也是很好的选择。如果你选择了 GTX 10 系列 GPU,请注意确保 GPU 显存大小可以满足你的要求。 那么对于深度学习,如何选择GPU?我的建议如下:
|